胸有成竹 (Xiōng yǒu chéng zhú) is a famous Chinese idiom, which translates to “having the bamboo formed in one’s mind before painting it.” It describes how the artist Wen Tong would fully envision his artwork internally before ever touching brush to paper.
This ancient concept mirrors a foundational idea described in Kenneth Craik’s 1943 book The Nature of Explanation, who posited that the human mind “translates” the external physical world into an internal mental model, arrives at other states through the manipulation of the internal model, and then “retranslates” those states back into the physical world. It’s exactly how naval engineers test a miniature model of the Queen Mary in a wave tank before laying down the actual ship’s hull.
Today, this concept is known in AI as a World Model—a term brought back into the spotlight by David Ha’s seminal 2018 paper, World Models.
While “world model” can take on various meanings depending on the context, this post focuses on its most popular interpretation in reinforcement learning (RL): a system that takes the current environment state and an action as inputs, and predicts the next state. This is the backbone of model-based RL, where an agent must actively learn the dynamics of its environment rather than having them pre-programmed.
In my previous post, we explored how Variational Autoencoders (VAEs) act as self-supervised learners, compressing complex environment states into compact latent embeddings. By training an additional transition model to take the latent representation and an action to predict the next latent representation, we successfully build a world model.
However, standard VAEs are notorious for producing blurry reconstructions. To fix this, we are upgrading our architecture: we’ll use a VQ-VAE to learn a discrete codebook of latent embeddings, paired with a GPT architecture to autoregressively learn the prior distribution of those embeddings.
For our dataset, we used the classic racing car environment. We collected 20,000 frame-action pairs by simply running the environment with random sampling.
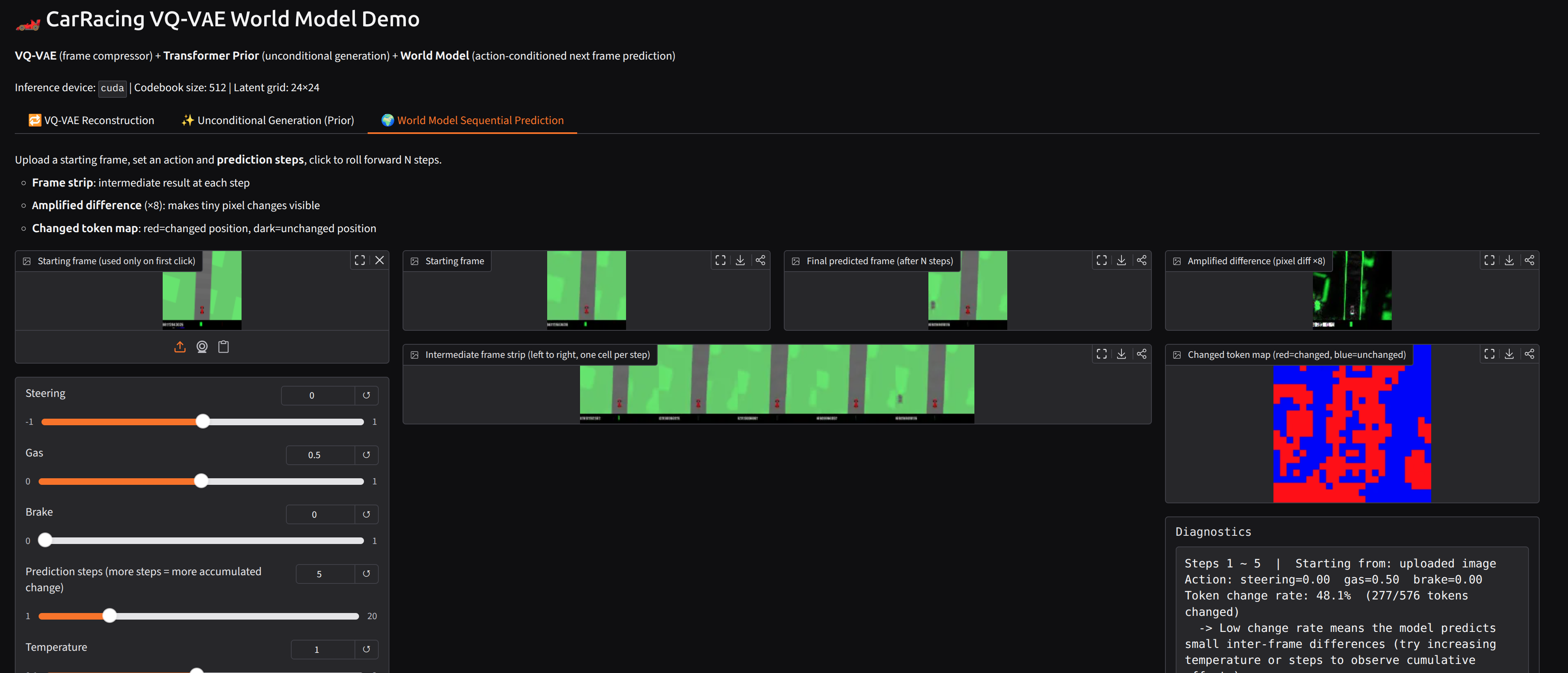
Here is the full reproduction code here. And below is a screenshot of the model’s prediction results.
Learnings
Data > Modeling: Model implementation is straightforward, but data collection is the real bottleneck.
Future Work
Browser Integration: Port the trained model and inference engine to JavaScript to create an interactive web demo (similar to David Ha’s racing car project).
Optimization: Address the technical challenges of web deployment, focusing heavily on model compression and latency reduction.